The Key/Value Store
The Key/Value store allows API Fortress users to create temporary key/value pairs that can be accessed across different tests. The Key/Value store is accessed via the Key/Value Store Component.
 An extremely important point to note is that these key/value pairs are temporary. They expire after 24 hours has elapsed since the last update to the value itself.
An extremely important point to note is that these key/value pairs are temporary. They expire after 24 hours has elapsed since the last update to the value itself.
The Key/Value Store Component has 4 methods available for use. They are:
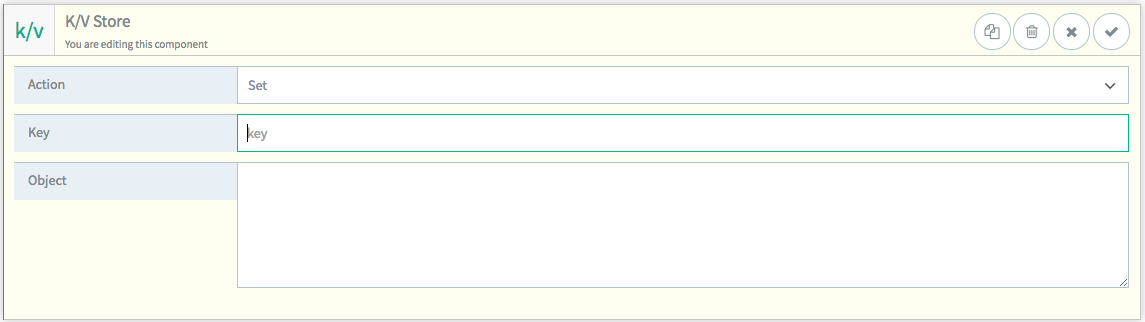
Set
Set will create a new key/value pair in the Key/Value store. The value is entered in the “
Object” field.
Load
Load will recall a value from the Key/Value store when provided with a key.

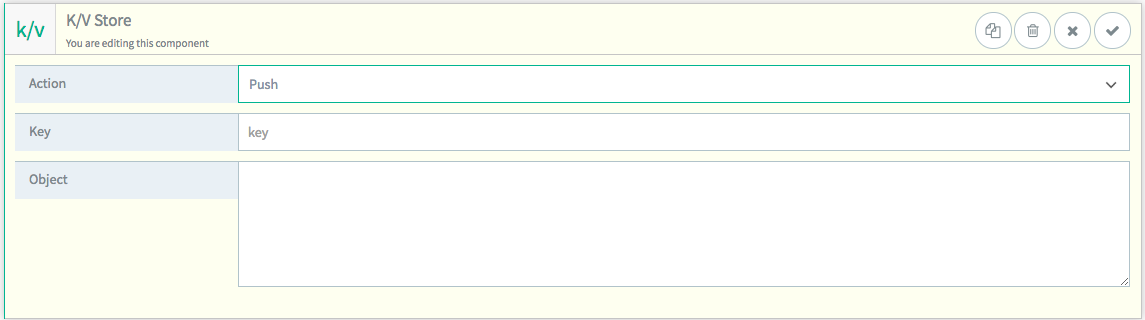
Push
Push will add a value to the end of an existent value
of the datatype “Array” in the Key/Value store.
If no such key exists, it will create a new array containing the passed in value. The passed in value is entered in the “
Object” field.
Pop
Pop will remove a value from the end of an existent value
of the datatype “Array” in the Key/Value store.

Basic Workflow
Let’s take a look at how this workflow works in a practical setting. The first example will be a simple set and retrieve of a value in the Key/Value Store.
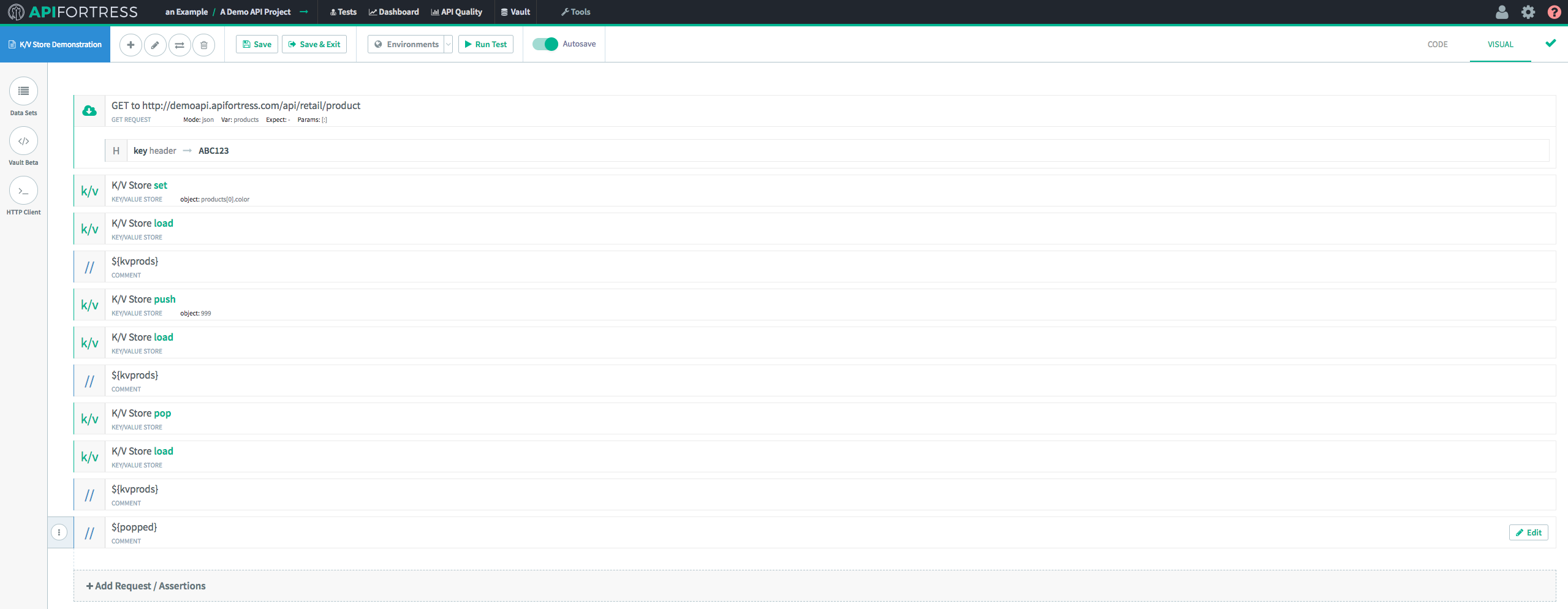
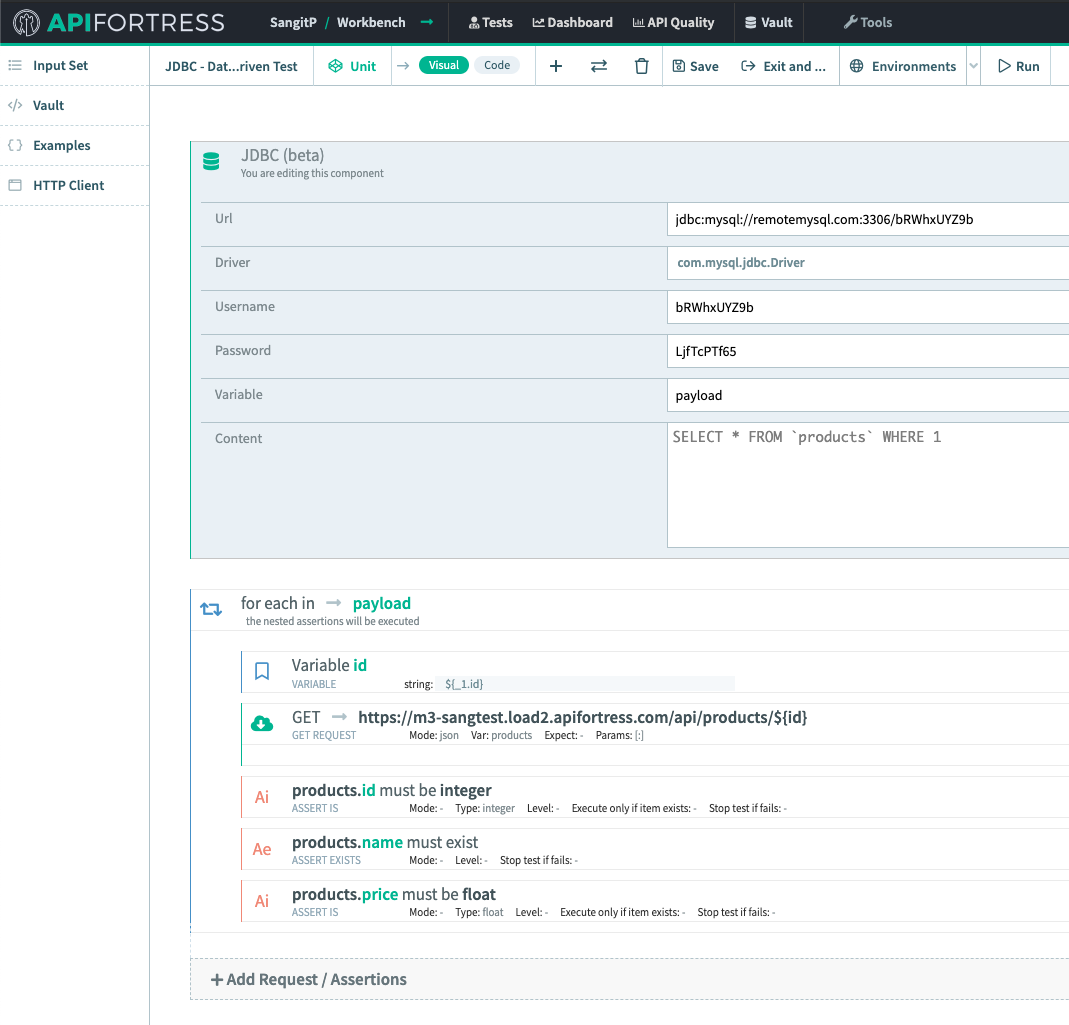
First, we’ll make a GET request to an endpoint.
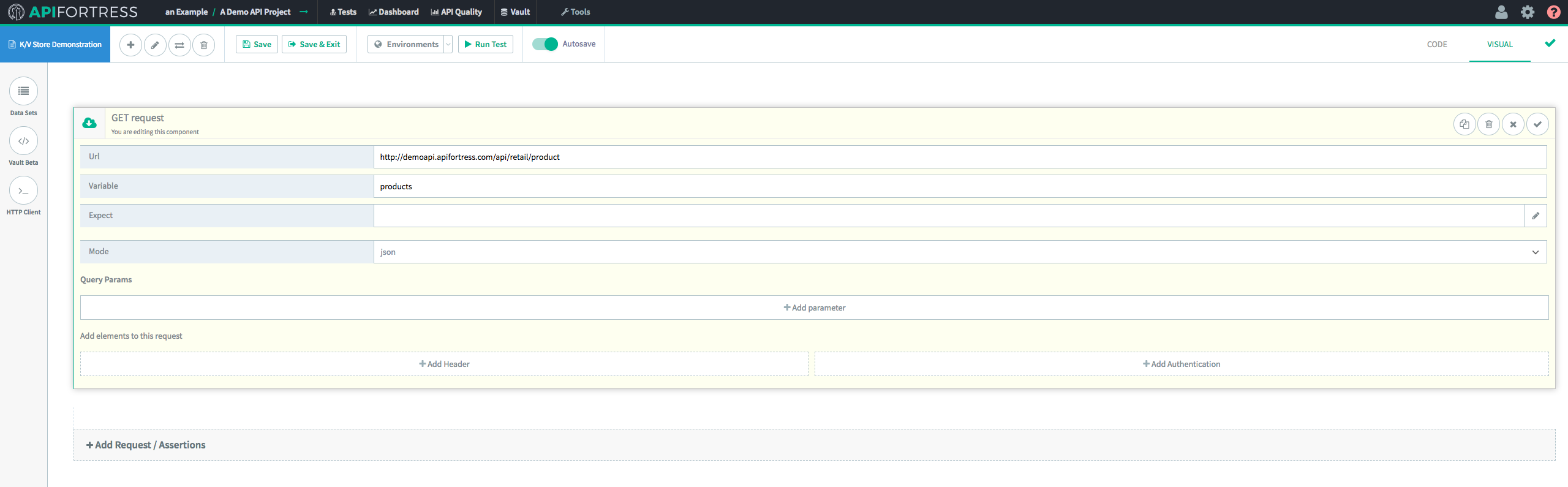
Next, we’ll add a K/V Store component.

This first K/V Store component (we’re going to incorporate several) is going to set the Key/Value pair in the Store, so we’re going to use “
Set.”
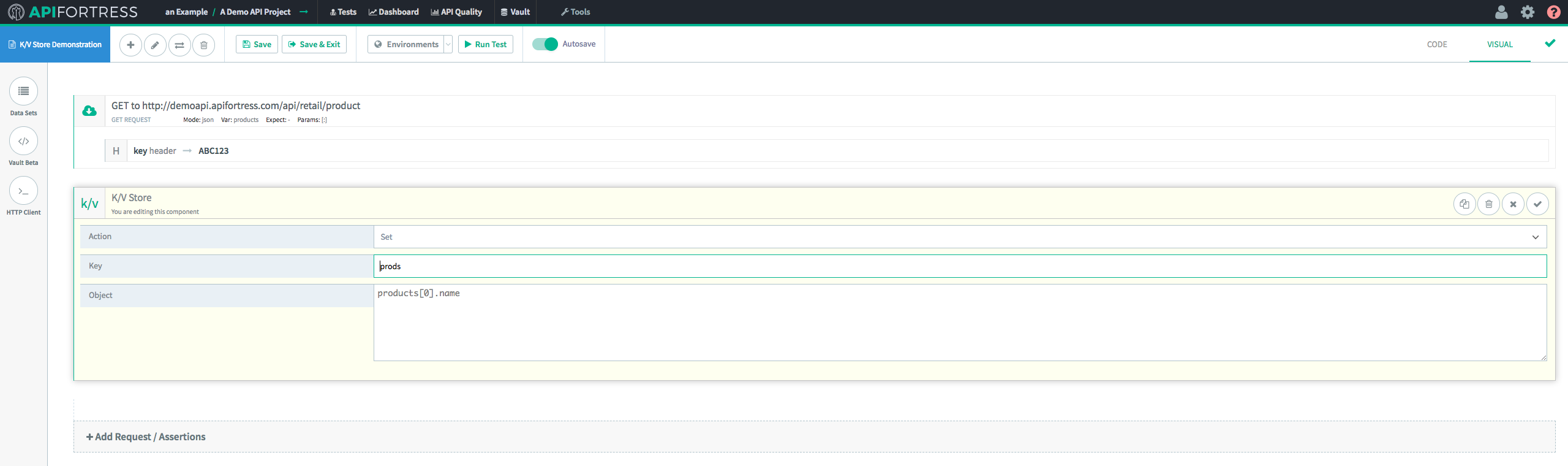
In this case we’re setting the Key “prods” equal to “products[0].name”, which in this case evaluates to “Baseball Cap.”
Next, we’re going to retrieve this Key/Value pair from the store with the “
Load” method. In the K/V Store “
Load” component, we’re going to assign the retrieved value to the variable “kvprods.”
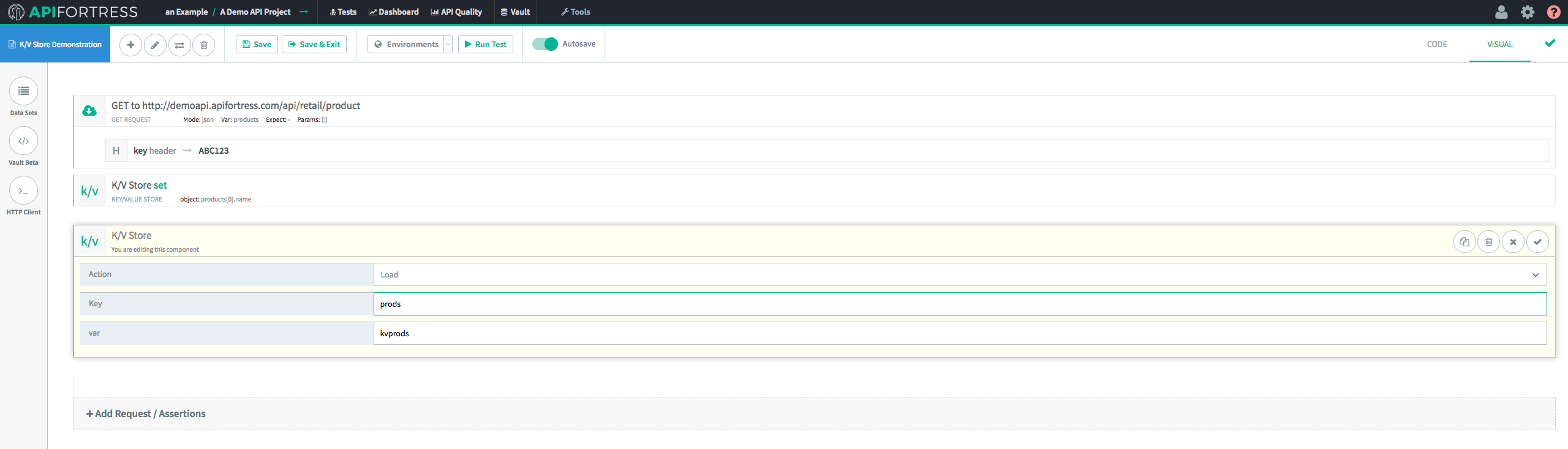
Finally, we’ll add in a “
Comment” component to ensure that the data was recovered successfully.
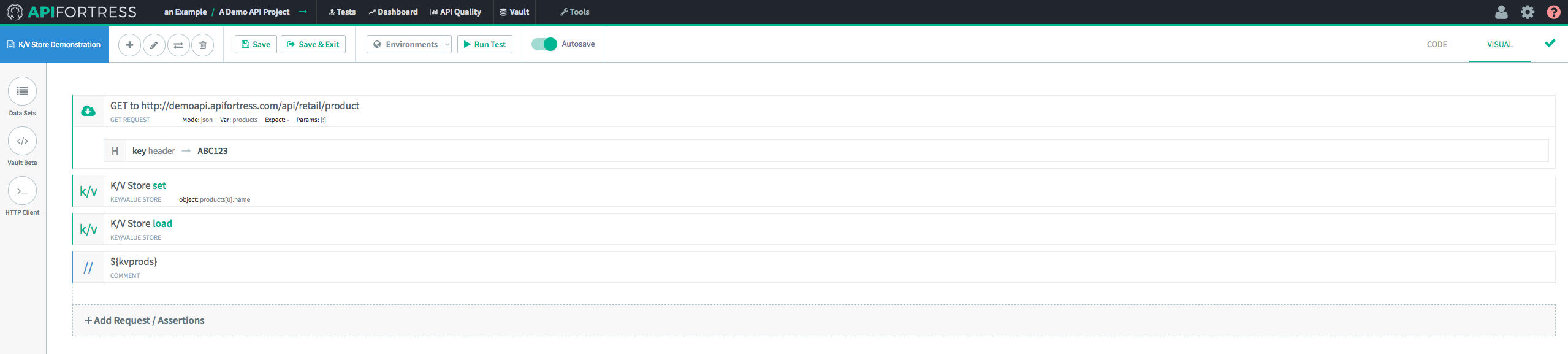
When we run the test, we’re presented with the following result:
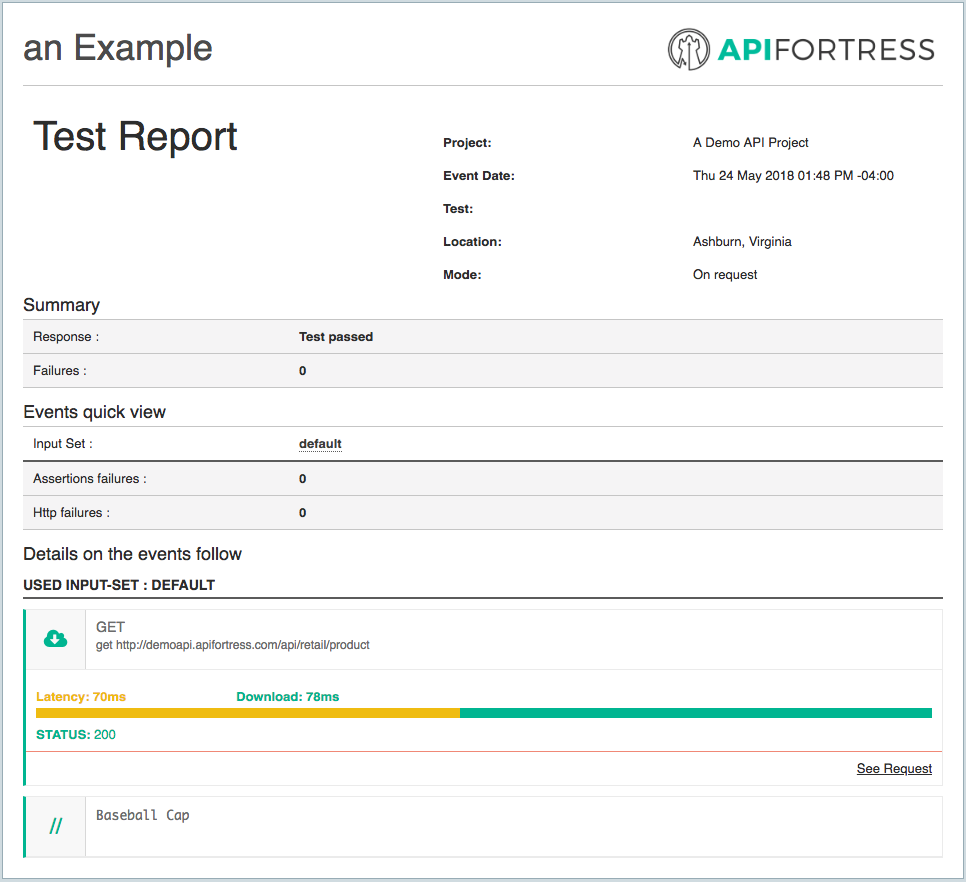
Success!
Push/Pop Workflow
Next, we’re going to take a look at how “
Push” and “
Pop” work. “
Push” and “
Pop” are both array methods and behave as they normally do outside of this context. “
Push” will append a value to the end of an array. “
Pop” will remove the last value in an array.
First, we’re going to use “
Push.” It should be noted that “
Pop” works similarly but with the opposite result. “
Pop”
also assigns the removed value to a variable which can be used in the context of the test, but can no longer be accessed from the Key/Value Store. We’ll discuss this further when we take a look at “
Pop.”
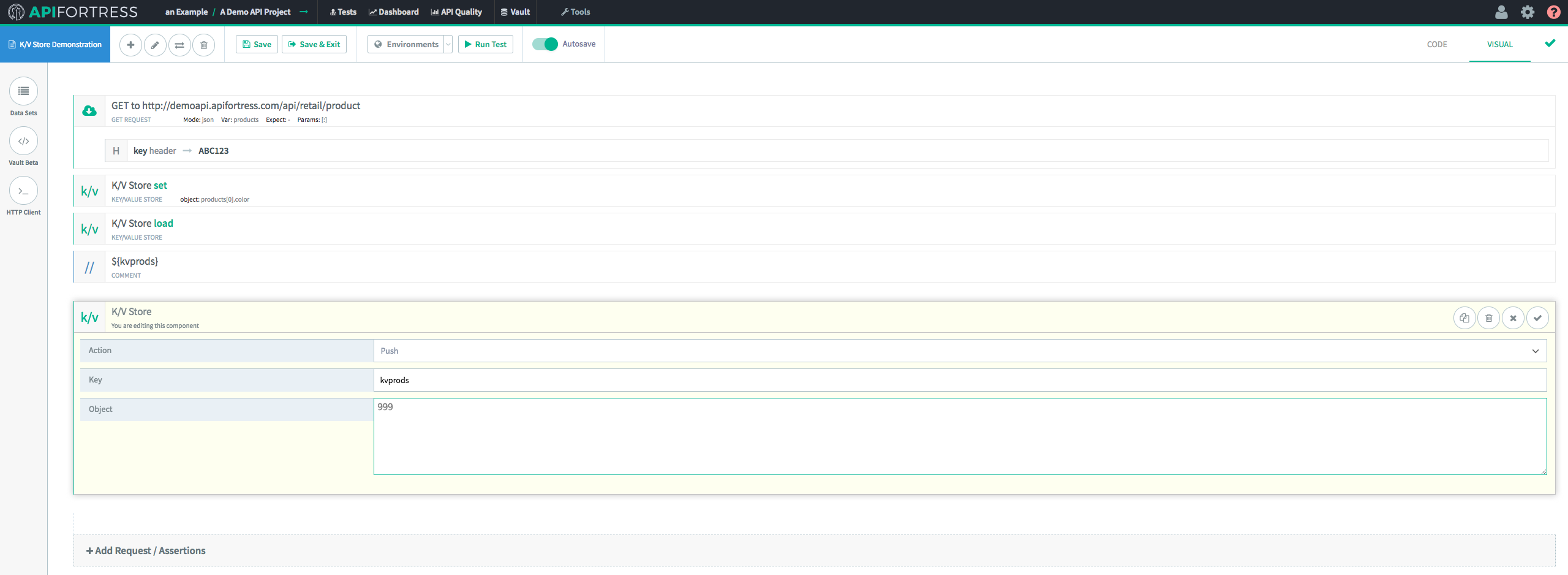
First, we’re going to send a GET request and assign a key in the Key/Value Store to a value from the response body. In this case, we’re going to use “Color,” which is an array.
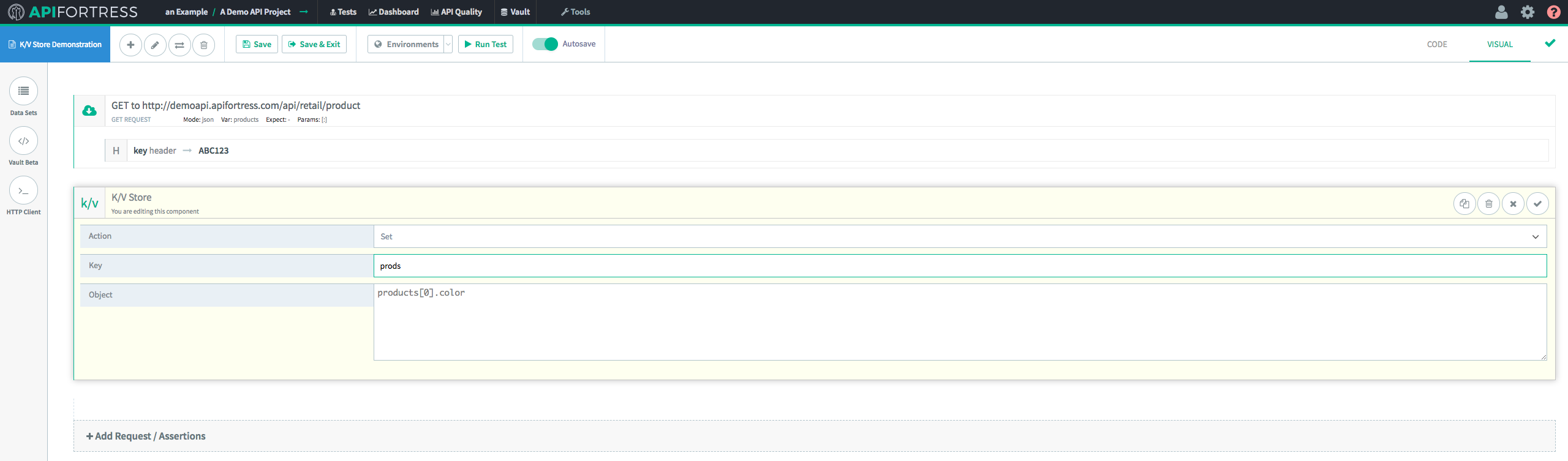
Next, we’re going to “
Load” and “
Comment” this key. We’re doing that so we can actually see the change on the test report at the end of this workflow.
The next step is to “
Push” the new data on to the end of the existing array.
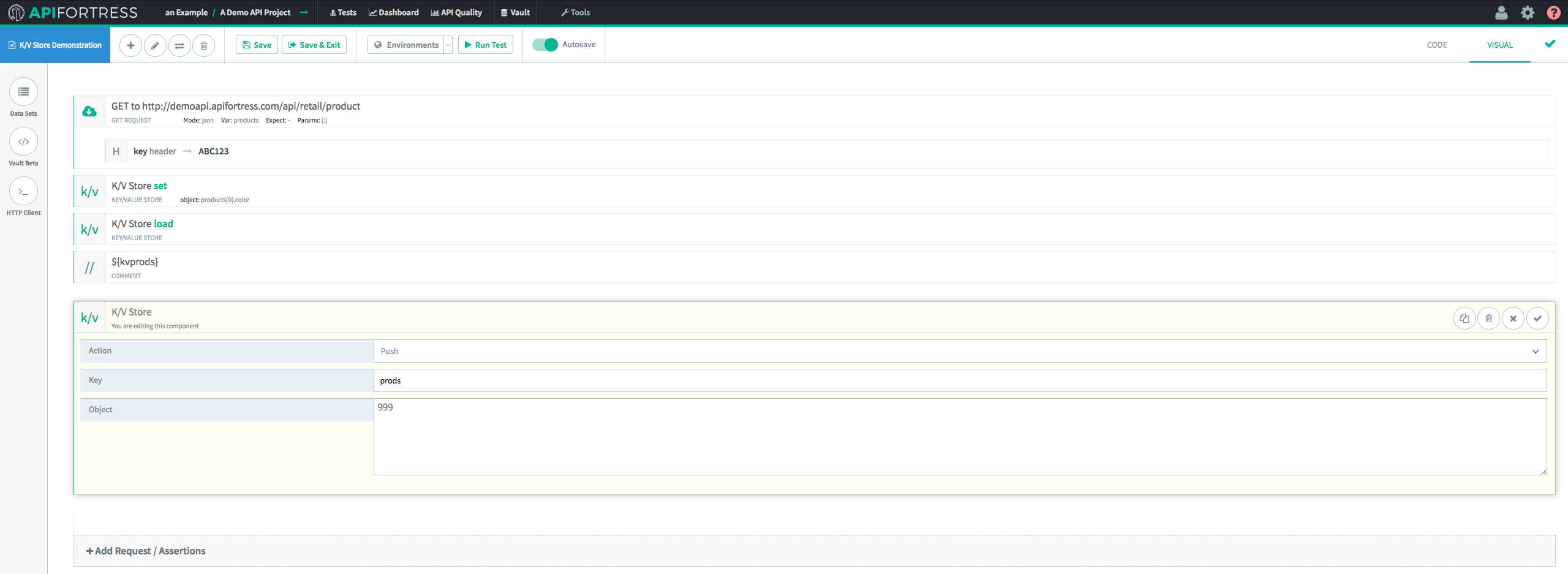
In this case, we’re pushing the integer
999 onto the
prods array.
Finally, we’re going to “
Load” the modified data into the test from the K/V Store.
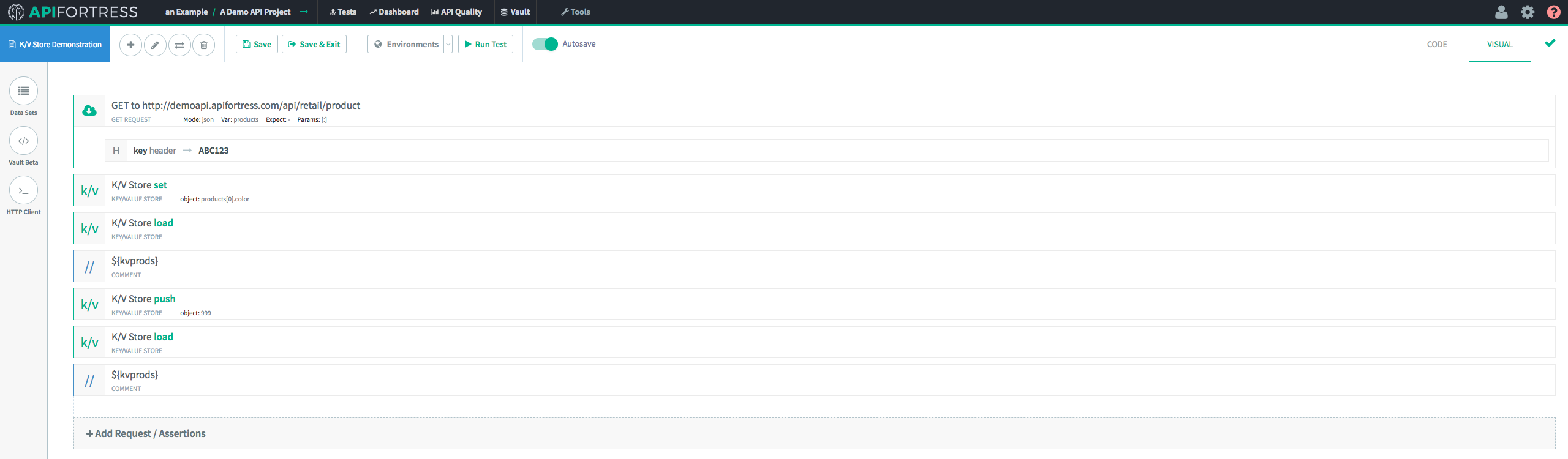
When we run the test, we’re presented with the following test report.
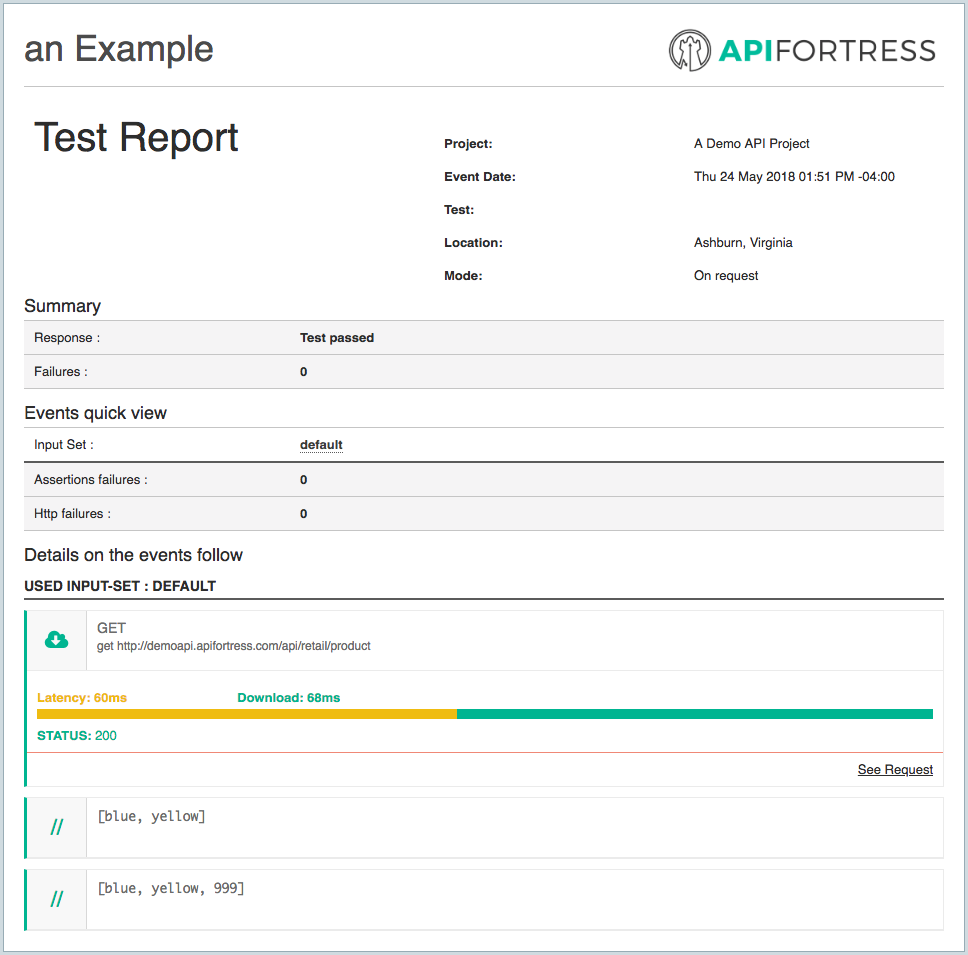
The comments show us clearly that we have pushed the number 999 onto the array stored in the key
prods.
Now, we’ve added something to the array. Let’s remove it with “
Pop!”
The first step is to introduce a “
Pop” K/V Store component.
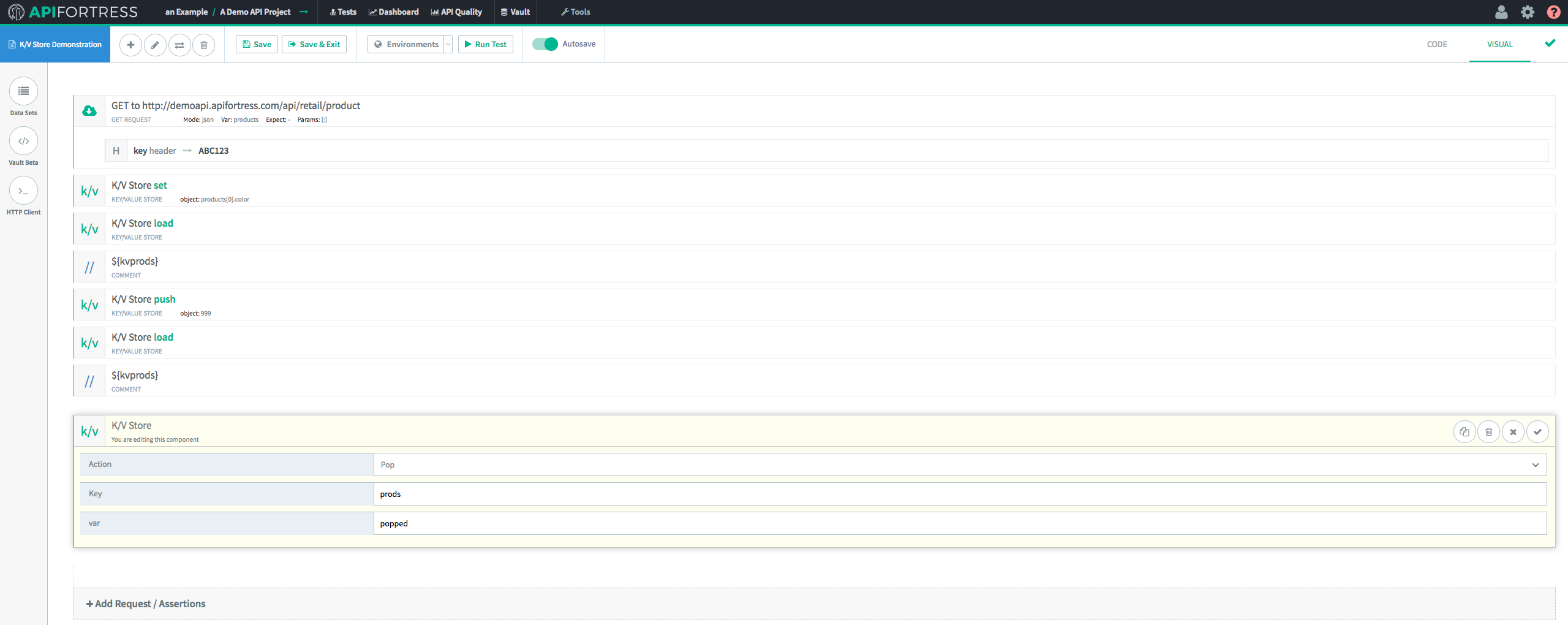
We provide the “Pop” component with the name of the key from the Key/Value Store, and the name of the variable we’d like to assign the popped value to. Remember, “
Pop” removes the last value in an array and returns the value itself. In this case, we’re going to assign it to a variable called “Popped.”
Next, we’re going to recall the modified key from the Key/Value Store. Then, we’re going to Comment both the recalled Key/Value Store value AND the previously popped value.
In the Test Report, we can clearly see the full workflow. First, we assigned an array to the Key/Value Store with “
Set.” Then, we added to that array with “
Push.” Finally, we removed the added value with “
Pop.” Each time we made a change, we used “
Load” to retrieve an updated value from the Key/Value Store.
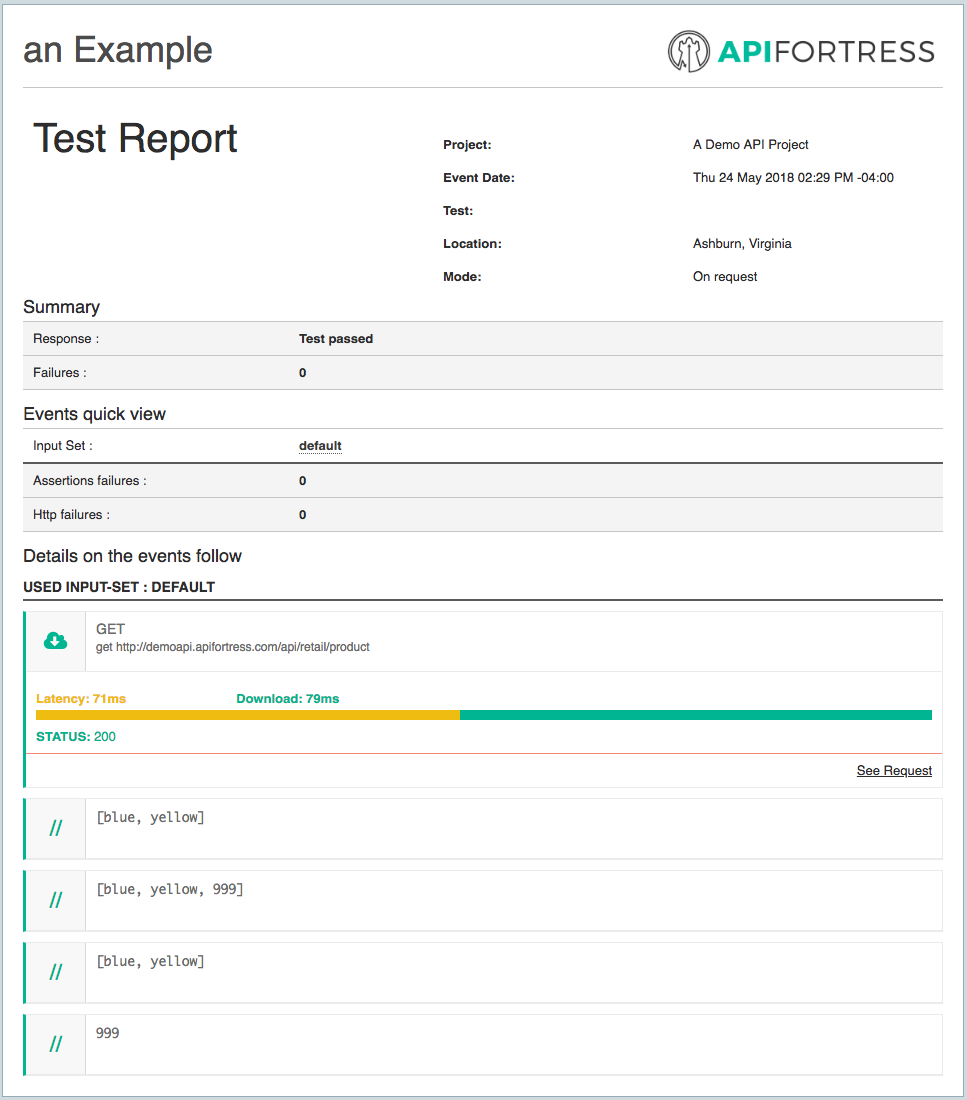
The last two comments show the final state of the array in the Key/Value Store and the popped value itself. The popped value will only be available within the scope of this test run. The array in the Key/Value Store will remain retrievable and until 24 hours after it’s most recent modification.
Note: “Load” does not reset the timer. Only “Set,” “Push,” and “Pop” reset the timer.


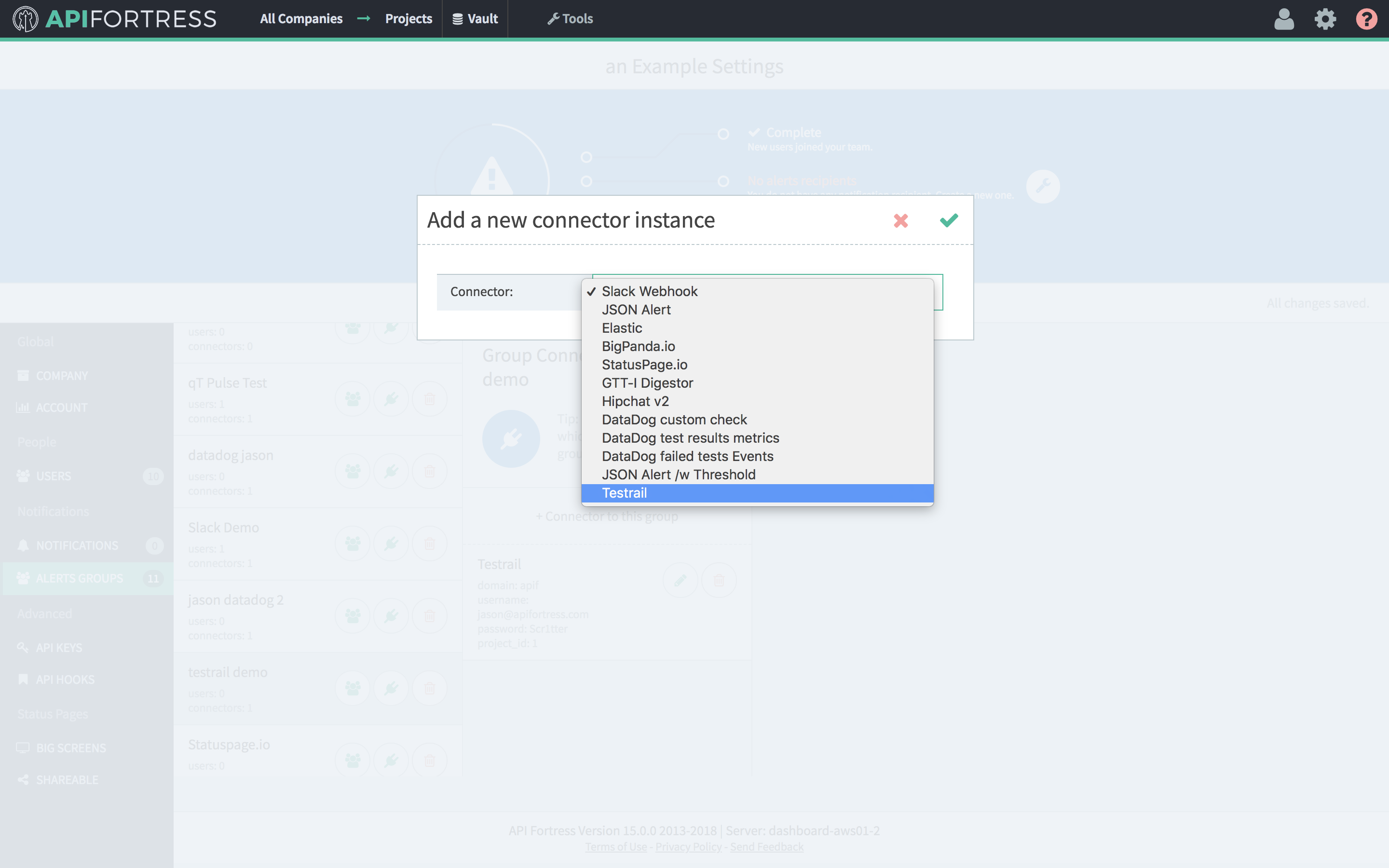

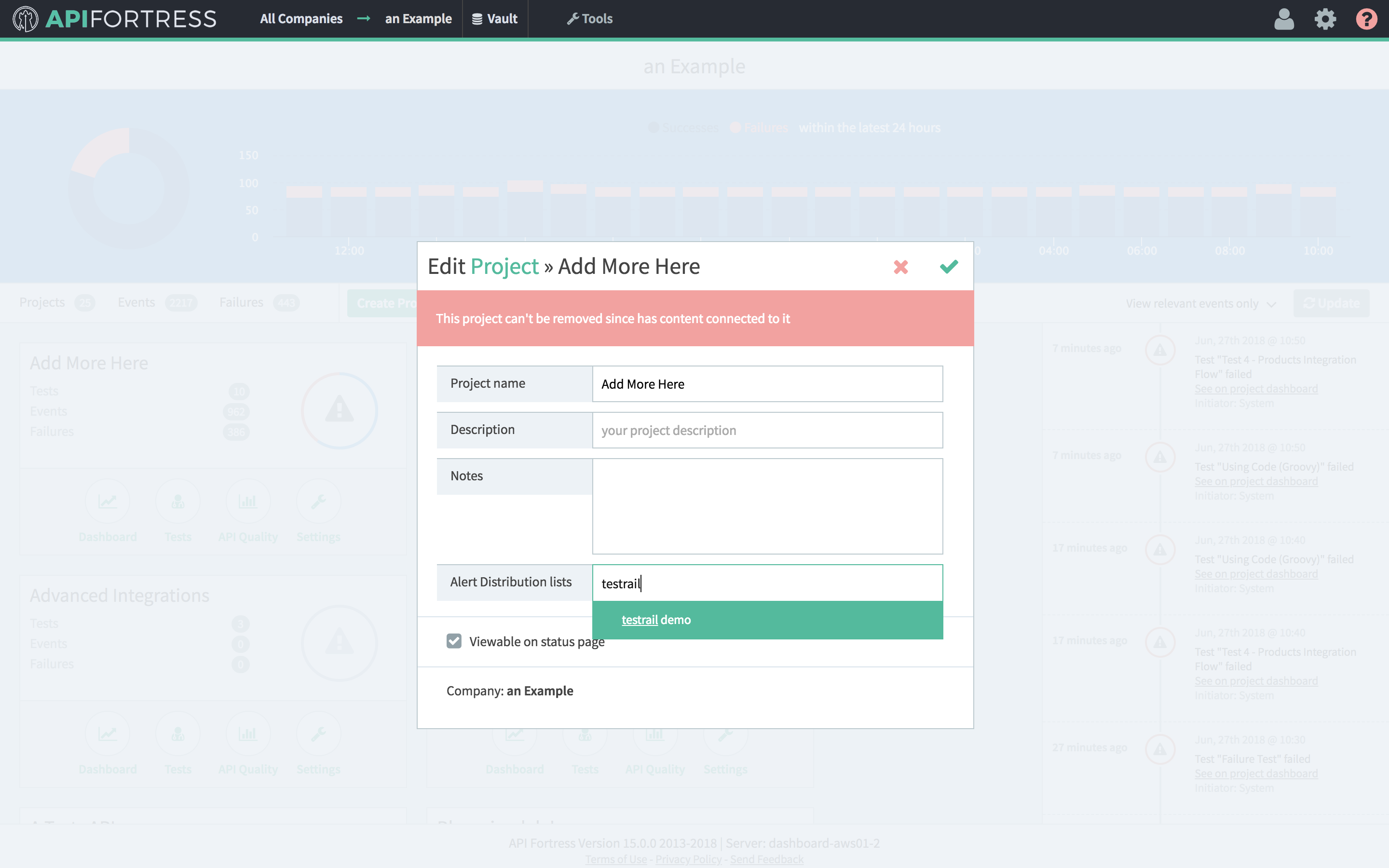
 Usually, the component is used in conjunction with the set variable component. First, we set a variable. Then, we make it available outside of the current test with the update input component.
We pass the update input component the name of the variable that we need to persist outside of the test. The component will first try to update a variable of the same name in the current input set. If that doesn’t exist, it will search for a global variable of the same name. If there is no global variable of the same name, it will check the vault. If the variable doesn’t exist there, it will create one with the same name.
Important note: the update input component works only outside of the composer. That is to say, it will only function when a test is executed from the Test List, the Scheduler, or via the API.
Usually, the component is used in conjunction with the set variable component. First, we set a variable. Then, we make it available outside of the current test with the update input component.
We pass the update input component the name of the variable that we need to persist outside of the test. The component will first try to update a variable of the same name in the current input set. If that doesn’t exist, it will search for a global variable of the same name. If there is no global variable of the same name, it will check the vault. If the variable doesn’t exist there, it will create one with the same name.
Important note: the update input component works only outside of the composer. That is to say, it will only function when a test is executed from the Test List, the Scheduler, or via the API.
 In the image above, after calling the login endpoint, we have created a variable called access_token with the set var component. Then, we have updated the value with the update input component. In doing so, the value of the variable will persist throughout and the value can be used in follow-on tests.
In the image above, after calling the login endpoint, we have created a variable called access_token with the set var component. Then, we have updated the value with the update input component. In doing so, the value of the variable will persist throughout and the value can be used in follow-on tests.
{kind=link}
{kind=link}